
هدف از مدلسازی، شناسایی رفتار دادههای وابسته به یکدیگر است که به واسطه آن بتوان تغییرات یک متغیر وابسته را برحسب متغیر یا متغیرهای مستقل بیان کرد. «رگرسیون» (Regression) یکی از تکنیکهای آماری به منظور مدلسازی است که به وفور در علوم دیگر بخصوص «یادگیری ماشین» (Machine Learning) به کار گرفته میشود. شیوه و روشهای مختلفی برای مدلسازی به سبک رگرسیون وجود دارد که یکی از آنها، «رگرسیون سلسله مراتبی» (Hierarchical Regression) نامیده میشود. در این نوشتار از مجله فرادرس به بررسی نحوه اجرای رگرسیون سلسله مراتبی در SPSS میپردازیم و البته مبانی و فرضیههای اولیه برای اجرای آن را نیز بیان خواهیم کرد.
رگرسیون سلسله مراتبی در SPSS
رگرسیون خطی سلسله مراتبی شکل خاصی از تحلیل رگرسیون خطی چندگانه است که در آن متغیرهای مختلفی در مراحل جداگانهای به نام «بلوک» (Block) و به شکل «پشتهای» (Stack) به مدل اضافه میشوند. البته این شیوه با روش رگرسیون گام به گام (Stepwise regression) متفاوت است. در رگرسیون گام به گام، هر متغیر بنا به اهمیتی که در مدل رگرسیونی دارد به مدل افزوده میشود و از طرفی به علت وجود ارتباط بین بعضی از متغیرهای مستقل، ممکن است در گام بعدی از مدل خارج شود.
در حالیکه در رگرسیون سلسله مراتبی، طبق نظر محقق و کاربر، متغیرها در بلوکهای متفاوت معرفی شده و به تعداد بلوکها، مدل ساخته میشود. در هر مدل، متغیرهای معرفی شده در بلوک، به بلوک قبلی افزوده شده و محاسبات مربوط به مدل جدید، صورت میگیرد.
این کار اغلب برای کنترل آماری متغیرهای خاص انجام میشود تا مشخص شود که آیا افزودن متغیرها، به طور قابل قبولی، توانایی مدل را در پیش بینی متغیر وابسته بهبود میبخشد یا خیر. به بیان دیگر یک متغیر وابسته، بیشتر تحت تاثیر کدام متغیرها مستقل قرار دارد و مدل اثر آنها چگونه است؟
به عنوان مثال، ممکن است بخواهید بدانید که آیا میزان «شادی افراد» (Happiness) با متغیرهای «سن»، «تعداد دوستان»، «جنسیت» و حتی «تعداد حیوانات خانگی»، رابطه دارد و آیا مدل ارتباطی برحسب کدام متغیرها، معنیدار خواهد شد یا خیر؟
البته برای پاسخ به این پرسش، میتوان از یک تحلیل رگرسیون خطی چندگانه منظم نیز استفاده کنیم تا ببینیم آیا این مجموعه از متغیرها (یعنی سن و تعداد دوستان و تعداد حیوانات خانگی) میزان خوشحالی را پیشبینی میکنند یا نه. با این حال، اگر فکر میکنید رابطه بین خوشحالی و سن در بین جنسیتهای زن و مرد، به چه شکل بوده یا تعداد دوستان یا حیوان خانگی در آن چه نقشی دارند، بهتر است از یک رگرسیون خطی سلسله مراتبی استفاده کنید تا به ترتیبی که در نظر شماست، مدل ساخته شود.
در بلوک اول، فقط دو متغیر پیش بینی کننده سن و جنسیت را به طور مستقل در نظر میگیریم و در بلوک دوم، یک متغیر دیگر (مثلا تعداد دوستان) را اضافه میکنیم. در آخر نیز هر چهار متغیر پیشبین را در مدل به کار برده و ضرایب و شرایط مدل رگرسیونی را مورد بررسی قرار میدهیم.
تحلیل رگرسیون سلسله مراتبی در SPSS
به تصویر زیر توجه کنید، متغیرها معرفی شده (مستقل و وابسته) در پنجره «نمای متغیرها» (Variable View) نرمافزار SPSS، دیده میشوند.variable view
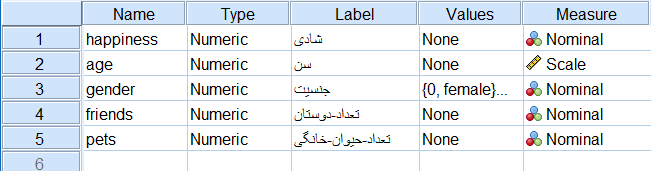

تصویر ۱: تعریف و نمایش اسامی متغیرها
در مدلی رگرسیونی، قرار است «شادی» (Happiness) را به عنوان متغیر وابسته، با استفاده از یک مدل رگرسیون سلسله مراتبی در SPSS با متغیرهای دیگر یعنی «سن» (age)، «جنسیت» (gender)، «تعداد دوستان» (friends) و «تعداد حیوان خانگی» (pets) برازش کنیم. در تصویر بعدی بعضی از مقادیر متغیرهای مربوط به ۱۰ مشاهده اول را میبینید. این فایل اطلاعاتی شامل ۱۰۰ مشاهده است که باید مدل را براساس آنها برازش دهیم.
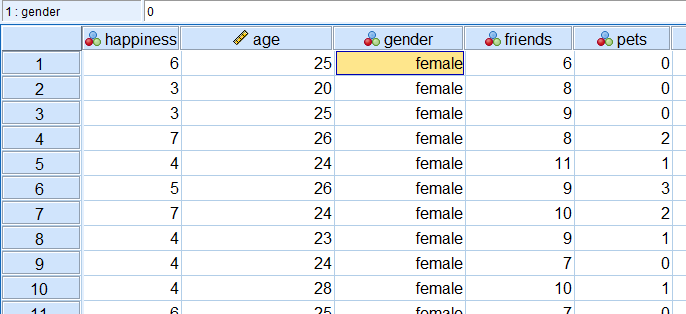

تصویر ۲: نمای داده در SPSS
توجه داشته باشید که متغیر جنسیت، به عنوان یک «متغیر طبقهای» (Categorical Variable) به کار رفته است و باید به صورت «دو وضعیتی» (Dichotomous) با مقادیر صفر و یک تعیین شود. اگر مقداری غیر از این دو مقدار در نظر بگیرید، عرض از مبدا مدل دچار تغییر شده و ممکن است با مقادیری که در این نوشتار به عنوان Constant در جدولها، ارائه شده، مطابقت نداشته باشد.
در ادامه به نحوه اجرای رگرسیون سلسله مراتبی در SPSS به کمک دستورات مربوط به مدل رگرسیون خطی عادی (OLS) خواهیم پرداخت. البته اجرای رگرسیون خطی در SPSS بسیار ساده و دقیق است. خوشبختانه یکی از آموزشهای فرادرس به نحوه اجرای رگرسیون OLS در محیط SPSS پرداخته است.
دستورات و نحوه اجرای رگرسیون سلسله مراتبی در SPSS
برای دسترسی به دستور اجرای رگرسیون خطی یا سلسله مراتبی و تعیین متغیرهای وابسته و مستقل، از مسیر زیر اقدام کنید.
Analyze — Regression — Linear
به این ترتیب، پنجرهای مطابق با تصویر ۳ ظاهر شده که توسط آن پارامترهای مدل رگرسیونی را مشخص میکنید. از آنجایی که متغیر شادی (Happiness) به عنوان متغیر وابسته در نظر گرفته شده، آن را در کادر Dependent قرار میدهیم.
برای تعیین متغیرهای مستقل به صورت سلسله مراتبی، ابتدا متغیرهای سن (age) و جنسیت را در کادر (Independent(s وارد میکنیم. به این ترتیب متغیرهای اولین بلوک (Block)، مشخص میشوند. برای تعیین بلوک یا گام بعدی در روند سلسله مراتبی، از دکمه Next استفاده کرده و در کادر (Independent(s، متغیر «تعداد دوستان» (friends) را مشخص کرده و با فشردن دکمه Next، بلوک بعدی برای متغیر مستقل را مشخص میکنیم. در این مرحله (بلوک سوم) متغیر «تعداد حیوانات خانگی» (pets) را در کادر (Independent(s قرار میدهیم.
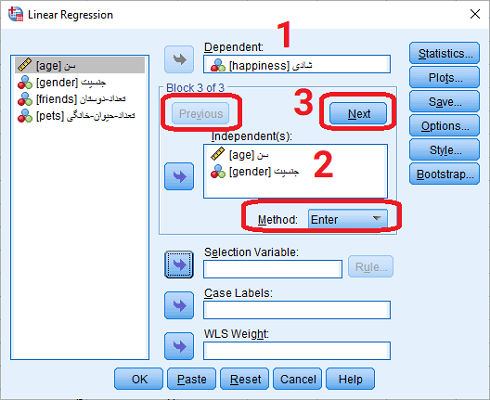

تصویر 3: تعیین پارامترهای رگرسیون سلسله مراتبی در SPSS
نکته: اگر در هر گام یا بلوک، اشتباهی رخداده باشد، میتوانید با دکمه Previous، به گام قبلی رفته و متغیرها را جابجا کنید. همچنین در نظر بگیرید که نوع ورود متغیرها در مدل، روی گزینه Enter در بخش Method تنظیم شده باشد.
پس از معرفی همه متغیرها، کافی است دکمه OK را کلیک کرده تا خروجی و محاسبات مربوط به برازش مدل رگرسیون سلسله مراتبی اجرا شود. در ادامه به تفسیر نتایج حاصل خواهیم پرداخت.
تفسیر خروجیهای رگرسیون سلسله مراتبی در SPSS
خروجی حاصل از رگرسیون سلسله مراتبی، درست به مانند الگویی است که در «رگرسیون خطی چندگانه» (Multiple Regression) مشاهده میکنید. مدلهای در نظر گرفته شده، براساس افزودن متغیرهای هر گام یا بلوک به گام یا بلوک قبلی، ساخته شده و ویژگیهای آن بوسیله جدولهایی، ارائه میشوند. فرض کنید که تنظیمها را براساس تصویر ۳ انجام دادهایم و نتایج را در پنجره خروجی SPSS ظاهر کردهایم.
در اولین جدول، مدلها به همراه متغیرهایشان معرفی شدهاند. از آنجایی که سه گام یا مرحله در رگرسیون سلسله مراتبی، طی شده، سه مدل نیز ساخته خواهد شد. به تصویر ۴ که متغیرهای مدل را معرفی کرده، توجه کنید.
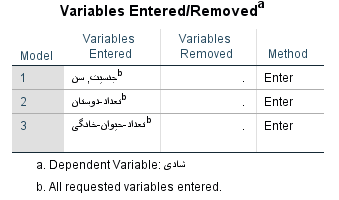

تصویر ۴: جدول متغیرهای مربوط به هر مدل رگرسیونی
همانطور که میبینید در مدل اول، دو متغیر «جنسیت» و «سن» به عنوان متغیرهای مستقل لحاظ شده و متغیر شادی نیز به عنوان متغیر وابسته به کار رفته است. به مدل دوم، متغیر «تعداد دوستان» و به مدل سوم نیز «تعداد حیوان خانگی» اضافه شدهاند.
نکته: از آنجایی که هنگام تعریف هر یک از متغیرها، برچسب فارسی در نظر گرفته شده، خروجیها نیز براساس برچسبها تولید شدهاند.
در جدول Model Summary، عملکرد بوسیله مقدار ضریب تعیین (R Square) برای هر یک از مدلها ارائه شده. این شاخص بیشترین مقدار وابستگی بین متغیر پیشبینی و مقدار واقعی را در مدل سوم نشان میدهد.
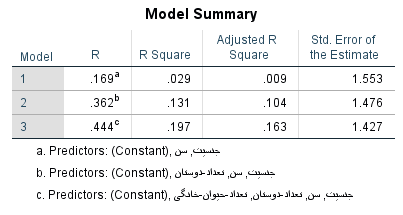

به نظر میرسد مدلی که همه متغیرهای مستقل در آن نقش دارند، بیشترین سهم را در توصیف متغیر وابسته داشته است. تقریبا ۲۰٪ از تغییرات متغیر وابسته توسط مدل شماره ۳، بیان میشود.
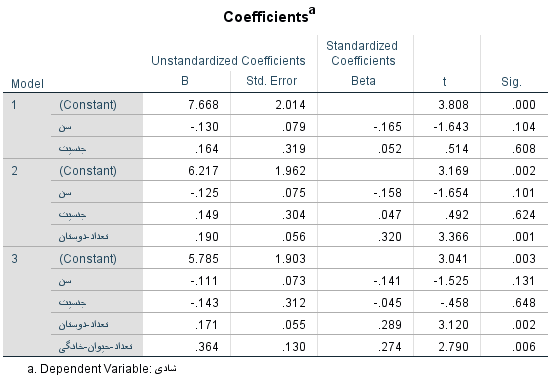

تصویر ۶: جدول آنالیز واریانس سه مدل رگرسیون
بیش از هر چیزی، جدول آنالیز واریانس یا تحلیل واریانس (ANOVA) برای نمایش قدرت برازش مدل رگرسیونی به کار میرود. به خوبی دیده میشود که به جز مدل اول، مدلهای دوم و سوم، دارای Sig (پی-مقدار ، p-Value) کوچکتر از ۰٫۰۵ هستند که نشانگر معنیدار بودن مدل انتخابی است. البته نسبت به ضرایب و پارامترهای مدل نیز باید آزمون فرض اجرا شود تا مشخص شود این مدلها به ازاء کدام متغیرها، معنیدار هستند.


تصویر ۷: جدول ضرایب مدل رگرسیون سلسله مراتبی در SPSS
در جدول بالا، ضریبهای متغیرها و همچنین عرض از مبدا (Constant) برای هر سه مدل ارائه شده است. از آنجایی که مدل اول، با توجه به جدول آنالیز واریانس، معنیدار نبود، از آن چشم پوشی میکنیم.
در مدل شماره ۲، به جز متغیر «تعداد دوستان»، متغیرهای دیگر معنیدار نبوده و مقدار Sig بزرگتر از ۰٫۰۵ دارند. از طرفی ضریب متغیر «تعداد دوستان» نیز برابر با ۰٫۱۹۰ است.
در مدل شماره 3، علاوه بر عرض از مبدا، متغیرهای «تعداد دوستان» و »تعداد حیوان خانگی» ضرایب معنیدار تلقی شده زیرا مقدار Sig برایشان از ۰٫۰۵ که سطح آزمون یا خطای نوع اول است، کمتر است. بنابراین میتوانیم این دو متغیر را در مدل رگرسیونی سلسله مراتبی به کار ببریم و دو متغیر دیگر را از مدل خارج کنیم.
نکته: از آنجایی که متغیر «تعداد حیوان خانگی» و «تعداد دوستان» دارای «ضریب استاندارد» (Standard Coefficient) تقریبا برابر (۰٫۲۷۴ و 0٫۲۸۹) هستند، میتوان اهمیت هر یک را در مدل رگرسیونی، یکسان در نظر گرفت.
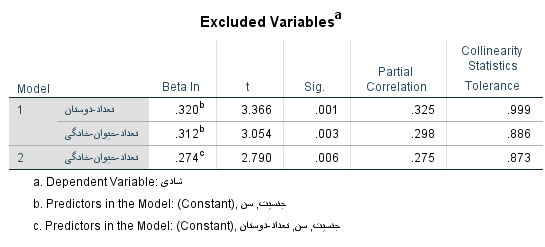

تصویر ۸: لیست متغیرهای خارج شده از مدلها
در انتها نیز متغیرهایی که در هر مدل از آنها استفاده نشده، در جدول Exclude Variables دیده میشود.
حال که متغیرهای مورد نظر استخراج شد، لازم است که یکبار دیگر مدل رگرسیونی را با لحاظ کردن دو متغیر «تعداد دوستان» و «تعداد حیوان خانگی» اجرا کرده و ضرایب را محاسبه کنیم. خروجی حاصل را در تصویر ۹ مشاهده میکنید.


تصویر ۹: خروجی مدل رگرسیونی برحسب متغیرهای مورد نظر
نکته: توجه داشته باشید که در این حالت هر دو متغیر را در کادر Independent و در بلوک اول رگرسیون سلسله مراتبی در SPSS وارد کردهایم.
ارزیابی مدل رگرسیون سلسله مراتبی
همانطور که میدانید، مدل رگرسیونی OSL، براساس نرمال بودن متغیر وابسته در هر سطح از متغیر مستقل ساخته میشود. به بیان دیگر، باقیماندههای مدل برازش شده باید شرطهایی که در ادامه آمدهاند را احراز کنند تا مدل ارائه شده، معتبر باشد. البته از آنجایی که در دیگر نوشتارهای مجله فرادرس به طور مفصل در مورد آنها صحبت شده، در اینجا فقط به لیستی از این شرطها اکتفا میکنیم. نحوه اجرای آزمونهای برازش در مدل رگرسیونی را میتوانید در روشهای رگرسیون در R — کاربرد در یادگیری ماشین مشاهده کنید.
میانگین جمله خطا باید صفر باشد،واریانس هر مولفه از جمله خطا ثابت و متناهی باشد.
جملات خطا از یکدیگر مستقل باشند،جملات خطا دارای توزیع نرمال با میانگین صفر و واریانس ثابت σ2باشند.
این شرطها کاملا با شرطهایی که در مدل رگرسیون OLS گفته شد، مطابقت دارند.
همبستگی و رگرسیون خطی در SPSS
برای ایجاد مدلهای آماری اغلب از رگرسیون استفاده میشود. به کمک شاخصهای محاسبه شده در این تکنیک آماری، مدل ارتباطی بین متغیرهای مستقل و وابسته مشخص شده و میتوان بر اساس مقادیر متغیرهای پیشگو، متغیر وابسته را پیشبینی کرد. در اغلب موارد برای مدل سازی، از رگرسیون خطی برای این کار بهره میبریم. در این فرادرس، مدل رگرسیون خطی (ساده و چندگانه) معرفی شده و نحوه اجرای آن در نرمافزار SPSS بازگو میشود. آزمونهای ارزیابی مدل رگرسیونی نیز از موضوعاتی است که میتوان در این فیلم آموزشی، مشاهده کرد. سرفصلی که در این درس به آن پرداخته شده، طبق فهرست زیر معرفی میشود.
همبستگی و رابطه بین دو متغیر: رابطه خطی مستقیم و معکوس، ضریب همبستگی پیرسون- Correlation Coefficient، آزمون مربوط به ضریب همبستگی پیرسون- Pearson Correlation Coefficient و ضریب همبستگی جزئی- Partial Correlation.
معادله خط برگشت Regression: متغیر مستقل و وابسته، فرضیات مربوط به شیوه محاسبه ضرایب رگرسیونی، فرض مربوط به نرمال بودن باقی ماندهها، فرض مربوط به ثابت بودن واریانس باقی ماندهها، فرض مربوط به تصادفی بودن باقی ماندهها، تعیین معادله خط رگرسیون با یک متغیر مستقل (برآورد ضرایب رگرسیون)، آزمونهای تعیین صحت مدل رگرسیون (Regression model) و تحلیل باقی مانده ها
رگرسیون چند متغیره: فرضیات مربوط به شیوه محاسبه ضرایب رگرسیونی، تعیین معادله خط رگرسیون با چند متغیر، آزمونهای تعیین صحت مدل رگرسیونی، روشهای کاهش تعداد متغیرهای مستقل (روش Backward-Forward-Stepwise) و بررسی شرایط مربوط به متغیرهای مستقل
بیشتر بدانیم :آموزش تحلیل مدلهای چند سطحی ( سلسله مراتبی خطی HLM)